

در این راهنمای کاربردی قرار است یاد بگیریم که خوشه بندی کلمات کلیدی با پایتون بر مبنای هدف جستجو انجام دهیم.
ما می خواهیم فرآیند دسته بندی عبارات را خیلی سریع تر و البته شهودی تر انجام دهیم.
این کار با تمرکز بر روش های تحقیق کلمه کلیدی و اولویت بندی نیاز مخاطب صورت می گیرد.
برای اینکه بتوانیم این دسته بندی را به درستی انجام دهیم باید دقیقا بر اساس هدف جستجو پیش برویم.
بحث های زیادی پیرامون نیت کاربر وجود دارد که باید به عنوان یک متخصص سئو به آن ها مسلط باشیم.
از به کارگیری یادگیری عمیق برای تشخیص هدف کاربر از روی متن گرفته تا تحلیل عناوین نتایج گوگل اهمیت دارد.
حتی استفاده از روش های پردازش زبان طبیعی و خوشه بندی طبق شباهت معنایی هم در این میان مطرح هستند.
ما نه تنها از فواید درک هدف کاربر آگاه هستیم بلکه تکنیک های زیادی هم برای خودکارسازی آن در اختیار داریم.
اما سوال اصلی اینجاست که با وجود این همه منابع چرا باز هم به یک مقاله جدید در این باره نیاز داریم؟
دلیل آن کاملا مشخص است و به تغییرات اخیر دنیای وب و ظهور فناوری های جدید مربوط می شود.
الان با ورود جستجوی مبتنی بر سئو و هوش مصنوعی موضوع درک و شناسایی نیت کاربر اهمیت خیلی بیشتری پیدا کرده است.
در گذشته گوگل بیشتر بر اساس همان ده لینک آبی کلاسیک نتایج را به کاربران نشان می داد.
در آن زمان تشخیص هدف کاربر آن قدرها هم پیچیده و حیاتی نبود و رقابت شکل دیگری داشت.
اما حالا با تکنولوژی جستجوی هوشمند شرایط کاملا فرق کرده است و سیستم ها بهینه تر شده اند.
چون این سیستم ها معمولا دنبال این هستند که هزینه های پردازشی را پایین نگه دارند و سریع تر نتیجه بدهند.
بهترین روش تحلیل هدف جستجو: چرا بررسی نتایج گوگل هنوز هم بیرقیب است؟
هنوز هم دقیقترین و مطمئنترین راه برای درک نیت کاربر، آنالیز مستقیم نتایج جستجوی گوگل (SERPs) است.
تا امروز روشهای متعددی برای کشف هدف جستجو معرفی شدهاند که اغلب به هوش مصنوعی ختم میشوند.
مثلاً مجبورید عناوین تمام محتواهای رتبهدار را جمعآوری کنید و به یک مدل پیچیده شبکه عصبی بدهید.
تازه این مدل را باید خودتان طراحی و تست کنید که کاری زمانبر و تخصصی است.
راه دیگر استفاده از پردازش زبان طبیعی (NLP) برای دستهبندی و انتخاب کلمه کلیدی است که آن هم چالشهای خودش را دارد.
اما اگر دانش فنی یا زمان کافی برای ساخت مدل هوش مصنوعی یا استفاده از APIهای گرانقیمت را نداشته باشید چه؟
درست است که شباهت کسینوسی به عنوان ابزاری برای طراحی ساختار وب سایت مفید است.
اما من همچنان معتقدم دستهبندی بر اساس نتایج جستجو دقیقترین و کاربردیترین روش موجود است.
دلیلش هم ساده است: هوش مصنوعی هم برای خروجی گرفتن از خودِ گوگل الهام میگیرد زیرا نتایج گوگل بر اساس رفتار واقعی کاربران شکل گرفتهاند.
یک روش هوشمندانه دیگر هم وجود دارد که از قدرت هوش مصنوعی خود گوگل بهره میبرد.
در این روش نیازی نیست کل نتایج را اسکرپ کنید یا درگیر ساخت مدلهای پیچیده شوید.
بیایید فرض کنیم گوگل سایتها را بر اساس احتمال پاسخگویی دقیق به نیاز کاربر رتبهبندی میکند.
بنابراین اگر هدف جستجو برای دو کلمه کلیدی یکسان باشد، نتایج جستجوی آنها هم بسیار شبیه به هم خواهد بود.
سالهاست که متخصصان با مقایسه نتایج جستجو سعی میکنند نیت کاربر را کشف کنند تا از آپدیت های الگوریتم های گوگل عقب نمانند.
پس این ایده جدید نیست، اما آنچه ارزشمند است اتوماتیک کردن این فرآیند مقایسه است.
این خودکارسازی باعث میشود هم سرعت کارتان چند برابر شود و هم دقت تحلیلهایتان افزایش یابد.
چطور کلمات کلیدی رو با توجه به نیت جستجو در مقیاس بالا خوشهبندی کنیم (با پایتون و کد نمونه)
فرض کنیم شما فایل نتایج جستجو (SERPs) رو برای مجموعهای از کلمات کلیدی بهصورت CSV دارید. حالا میخوایم این فایل رو وارد پایتون کنیم و قدم به قدم برای خوشهبندی موضوعی بر اساس نیت جستجو آمادهاش کنیم.
1. وارد کردن فایل SERP در پایتون
در این مرحله، با استفاده از کتابخانههای Pandas و NumPy، فایل CSV رو به یه دیتافریم (DataFrame) تبدیل میکنیم:
با اجرای این کد، فایل SERP شما وارد محیط پایتون میشه و حالا آمادهایم تا شروع به فیلتر کردن نتایج کنیم.
2. فیلتر کردن نتایج صفحه اول گوگل
هدف اینه که فقط نتایج صفحه اول گوگل برای هر کلمه کلیدی رو نگه داریم، چون دقیقترین سیگنالها از نیت جستجو معمولاً توی همین صفحه هستن.
برای این کار، دیتافریم رو بر اساس کلمه کلیدی گروهبندی میکنیم، نتایج فاقد URL یا رنک بالاتر از ۱۵ رو حذف میکنیم، و دوباره همه چیز رو به یه جدول واحد تبدیل میکنیم:
حالا یه جدول تمیز داریم که فقط شامل نتایج صفحه اول برای هر کلمه کلیدی هست و آمادهایم که وارد مراحل بعدی برای خوشهبندی موضوعی بشیم.

۳. تبدیل URLهای نتایج جستجو به یک رشته برای هر کلمه کلیدی
تا اینجای کار، برای هر کلمه کلیدی، چندین URL مربوط به صفحه اول نتایج جستجو داریم. اما چون میخوایم در نهایت بتونیم مقایسه راحتتری بین کلمات کلیدی انجام بدیم، لازمه که همهی URLهای مربوط به یک کلمه رو به صورت یک رشتهی متنی توی یک خط جمع کنیم.
درواقع داریم برای هر کلمه کلیدی، یه نمای کلی از نتایج صفحه اول گوگل رو به شکل یه متن ساده در میاریم.
نحوه انجام کار:
در نهایت، برای هر کلمه کلیدی، یه رشتهی متنی داریم که شامل تمام URLهای صفحه اول اون کلمهست. این ساختار جدید خیلی به کار ما برای مرحله بعدی یعنی تحلیل شباهت و خوشهبندی موضوعی کلمات کلیدی کمک میکنه.
۴. مقایسه فاصله نتایج جستجو (ادامه)
برای اینکه مقایسه بین نتایج جستجوی گوگل (SERP) به درستی انجام بشه، باید هر کلمه کلیدی رو با سایر کلمات موجود جفت کنیم و نتایجشون رو در کنار هم قرار بدیم.
در این کد پایتون، تابع serps_align طراحی شده تا دقیقاً همین کار رو انجام بده. این تابع برای یک کلمه کلیدی خاص، تمام SERPهای دیگر کلمات رو کنار اون قرار میده و آماده مقایسه میکنه. به زبان ساده، این تابع، دادهها رو طوری تنظیم میکنه که بشه بررسی کرد آیا نتایج جستجو برای کلمات مختلف به هم شباهت دارن یا نه.
تصویری که بالا نشون داده شده، تمام ترکیبهای ممکن بین SERPهای کلمات کلیدی رو نشون میده و حالا آماده مقایسه دقیق متن نتایج جستجو هستیم.
نکته مهم اینجاست که هیچ کتابخانه متنباز (Open-source library) شناختهشدهای وجود نداره که بتونه لیستهای نتایج جستجو رو بر اساس ترتیب آیتمها با هم مقایسه کنه. به همین خاطر، تابعی برای این کار نوشته شده.
این تابع با نام serp_compare طراحی شده تا میزان اشتراک بین سایتها و ترتیب نمایش اونها رو در بین دو SERP بررسی کنه. این مقایسه به شما کمک میکنه تا متوجه بشید که کلمههای کلیدی مشابه چقدر از نظر نتایج به هم نزدیک هستن، و این موضوع میتونه در بهینهسازی ساختار سایت و استراتژی سئو نقش خیلی مهمی داشته باشه.
حالا که مقایسهها انجام شده، میتونیم خوشهبندی کلمات کلیدی رو شروع کنیم.
ما هر کلمه کلیدیای که شباهت وزنی (weighted similarity) بینشون ۴۰ درصد یا بیشتر باشه رو در یک گروه یا خوشه قرار میدیم.
این کار به ما کمک میکنه کلمات کلیدی مرتبط رو کنار هم داشته باشیم و بتونیم برای هر خوشه، محتوای بهتری تولید کنیم که به رشد سایت در نتایج گوگل کمک زیادی میکنه.
حالا ما اسم احتمالی موضوع، شباهت نتایج جستجوی کلمات کلیدی (keywords SERP similarity) و حجم جستجوی هر کدوم رو داریم.
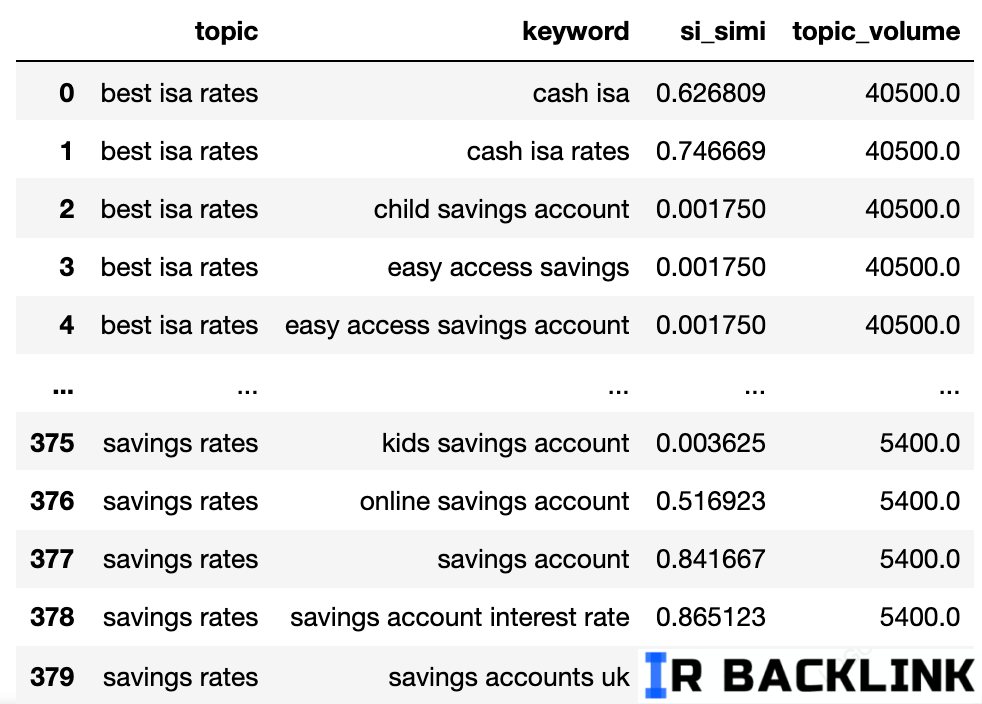
توجه کن که ستونهای keyword و keyword_b به ترتیب به topic و keyword تغییر نام دادن.
حالا قراره روی ستونهای دیتافریم با استفاده از تکنیک lambda تکرار (iterate) کنیم.
تکنیک lambda یک روش بهینه و سریع برای تکرار روی ردیفهای دیتافریم پانداس (Pandas) هست، چون برخلاف تابع معمول .iterrows()، ردیفها رو به لیست تبدیل میکنه و این باعث افزایش سرعت اجرای کد میشه.
خب، بریم سراغ کد:
در ادامه، یک دیکشنری (فرمت دادهای) میبینیم که تمام کلمات کلیدی رو بر اساس نیت جستجو (Search Intent) به گروههای شمارهدار تقسیم کرده.
حالا این دادهها رو داخل یک دیتافریم (DataFrame) قرار میدیم.
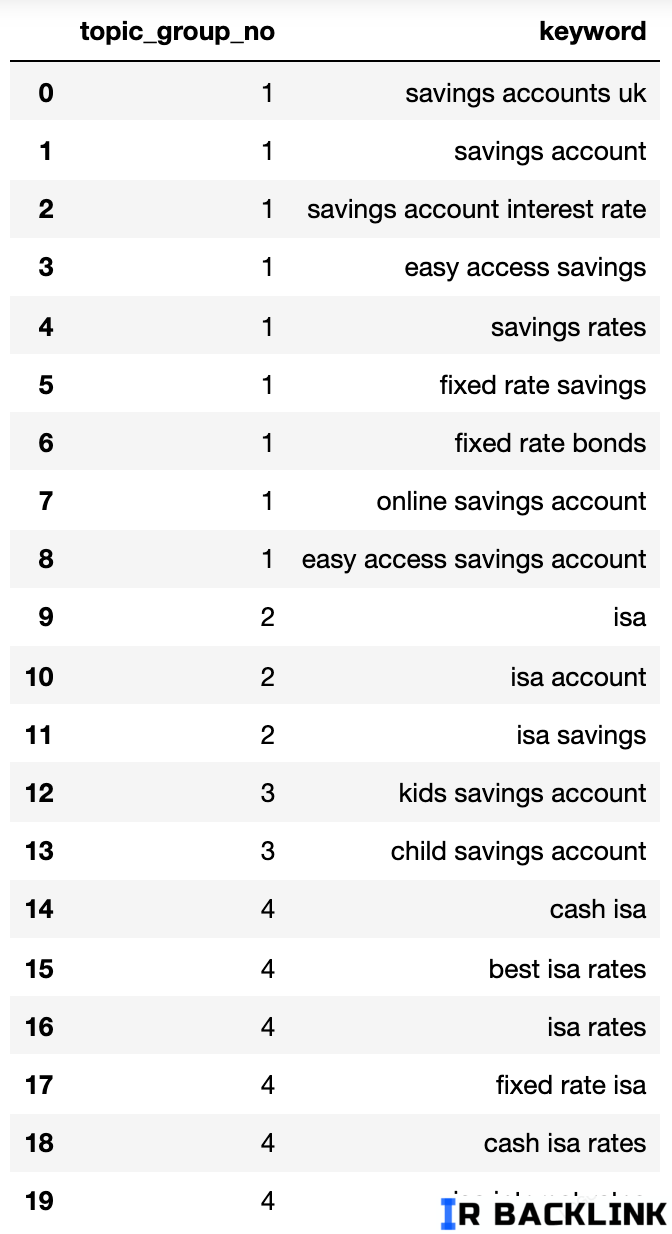
گروههای نیت جستجو که بالا دیدیم، تقریب خوبی از کلمات کلیدی داخل هر گروه نشون میدن — چیزی که یک کارشناس حرفهای سئو معمولاً بهش میرسه.
هرچند ما فقط از یه مجموعه کوچک از کلمات کلیدی استفاده کردیم، اما این روش به راحتی میتونه برای هزاران کلمه کلیدی (یا حتی بیشتر) گسترش پیدا کنه.
کاربردهای عملی خوشه بندی برای ارتقای استراتژی سئو
البته که این فرآیند پتانسیل این را دارد که بسیار فراتر از یک دستهبندی ساده پیش برود.
ما میتوانیم با بهرهگیری از سئو و هوش مصنوعی محتوای رتبهبندی شده را عمیقتر تحلیل کنیم.
استفاده از شبکههای عصبی کمک میکند تا نامگذاری گروهها دقیقتر انجام شود دقیقاً مثل کاری که ابزارهای تجاری بزرگ انجام میدهند.
اما در حال حاضر و با همین خروجیهای فعلی هم میتوانید کارهای بزرگی انجام دهید.
شما میتوانید این روش را وارد داشبوردهای مدیریتی خود کنید تا گزارشهای سئو برایتان معنیدارتر شود.
همچنین میتوانید کمپینهای تبلیغاتی خود را بهینه کنید و حسابهای گوگل ادز را بر اساس نیت کاربر بچینید.
این کار باعث میشود امتیاز کیفی تبلیغات شما به شدت افزایش پیدا کند.
یکی دیگر از کاربردها ادغام آدرسهای مشابه در فروشگاههای اینترنتی برای جلوگیری از ایجاد محتوای تکراری است.
شما میتوانید طبقهبندی محصولات در سایتهای فروشگاهی را به جای مدل کاتالوگی بر اساس ساختار وب سایت مدرن و نیاز کاربر بنا کنید.
این تغییر رویکرد مستقیماً روی بهبود تجربه کاربری و افزایش رضایت مشتریان تاثیر میگذارد.
مطمئنم کاربردهای خلاقانه دیگری هم وجود دارد که شاید من در اینجا به آنها اشاره نکرده باشم.
اگر ایدهای به ذهنتان رسید خوشحال میشوم آن را در بخش نظرات با ما در میان بگذارید.
در نهایت باید گفت که روش های تحقیق کلمه کلیدی شما اکنون دقیقتر و سریعتر شده و قابلیت گسترش بالایی دارد.
کد کامل رو میتونید برای استفاده خودتون از اینجا دانلود کنید.
کد نهایی و مناسب شده برای عبارات فارسی به صورت کامل :
ترجمه : How To Automate SEO Keyword Clustering By Search Intent With Python

من، جعفر جلالی، سایت ایران بک لینک را راهاندازی کردم. با تکیه بر تجربیاتی که طی سالها در کسبوکارهای آنلاین به دست آوردهام و همچنین استفاده از منابع اصلی و معتبر انگلیسی، تلاش کردم بهترین مقالات و منابع آموزشی در زمینه سئو را به زبان فارسی گردآوری کنم. هدف من از ایجاد ایران بک لینک این است که به کسبوکارهای آنلاین کمک کنم تا با دسترسی به اطلاعات کاربردی و جامع، به موفقیت بیشتری دست پیدا کنند. امیدوارم که ایران بک لینک بتواند به منبعی قابلاعتماد برای شما تبدیل شود.